우선 JVM이란?
자바 가상 머신이라 부른다.
자바와 운영체제사이에서 중계자 역할을 한다.
자바가 운영체제 종류에 영향받지 않고 돌아갈 수 있도록 한다.
메모리 관리를 자동으로 해준다 (GC)
여기서 중요한 것은 운영체제와 플랫폼 종류에 의존적이지 않고 독립적으로 JAVA프로그램이 실행된다.

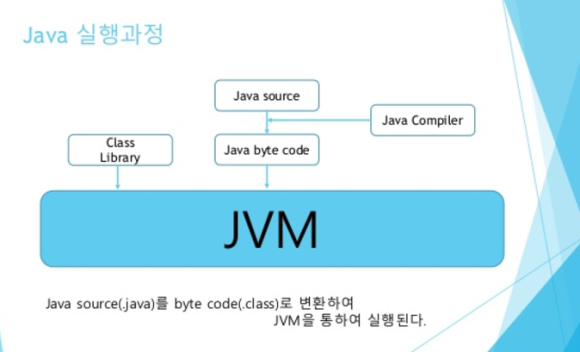
위 그림을 설명하면...
Java Compiler(자바 컴파일러)에 의해 Java source(.java) 파일은 Byte code로 변환된다.
Class Loader(클래스 로더)는 이 변환된 Byte code(.class) 파일을 JVM 내로 class를 로드하고 Link작업을 통해
배치 등 일련의 작업을 한다. 또 런타임시 class를 load한다.
Execution Engine(실행 엔진) 은 Class Loader를 통해 JVM 내부로 넘어와 Runtime Data Area(JVM 메모리)에 배치된
Byte code들을 명령어 단위로 실행시킨다.
GC(Garbage Collector)는 어플리케이션이 생성한 객체의 생존 여부를 판단하여, 더이상 참조되지 않거나 null 인 객체의 메모리를 해체시켜
메모리 반납을 한다.
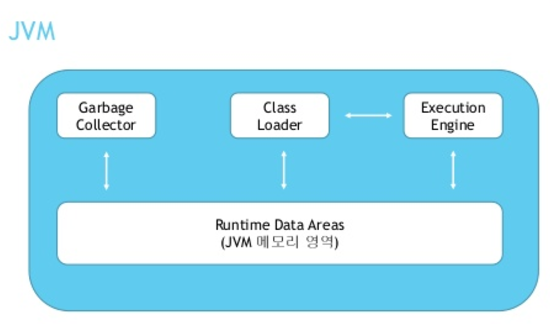
Runtime Data Areas(JVM 메모리) 런타임 데이터 영역은 JVM메모리로 Java 어플리케이션이 실행하면서 할당받은 메모리영역이다.
세분화하자면 6개(Method, Runtime Constant Pool, Heap, Stack, PC Register, Native Method Stack)의 영역으로 나뉜다.

출처 : http://hoonmaro.tistory.com/19
6개 메모리 영역의 용도와 특징
(화질이 좋지 않으니 클릭해서 보시길.)

끝으로 Heap Area를 좀 더 살펴보면....
Young Generation : 객체가 생성될 때 저장된다. 즉 막 생성된 객체들의 인큐베이터이다. 생성된 기간이 흐르고, 우선순위가 낮아지면
Young 세대의 객체들은 Old세대로 이동하게 된다. 이 영역에서 객체가 사라질 때는 Minor GC 수행된다.
Old(Tenured) Generation : Young Generation 영역에 있는 객체가 오래되서 저장되는 공간이다.
이 영역에서 객체가 사라질 때는 Major GC(Full GC) 수행된다.
Permanent Generation : 클래스 로더에 의해 로든되는 클래스, 메소드 등에 대한 메타 정보가 저장되는 영역으로 JVM에 의해 사용된다. 리플렉션을 사용하여 동적으로 클래스가 로딩되는 경우에 사용된다.
또 Method와 Runtime Constant Pool , Heap 영역은 모든 스레드에서 공유할 수 있다.
'프로그래밍 > OS' 카테고리의 다른 글
| 리눅스 which ,where ,locate (0) | 2018.07.21 |
|---|---|
| 리눅스 touch - 파일생성 및 파일의 날짜정보 변경 (0) | 2018.07.21 |
| JVM 메모리 구조에서 method 의 저장위치 의 애매한 개념에 대한 정확한 답변 (0) | 2018.04.21 |
| JVM(JavaVirtualMachine) (0) | 2018.04.21 |
| Process 와 Thread 의 차이 (0) | 2018.04.16 |

낭만가을